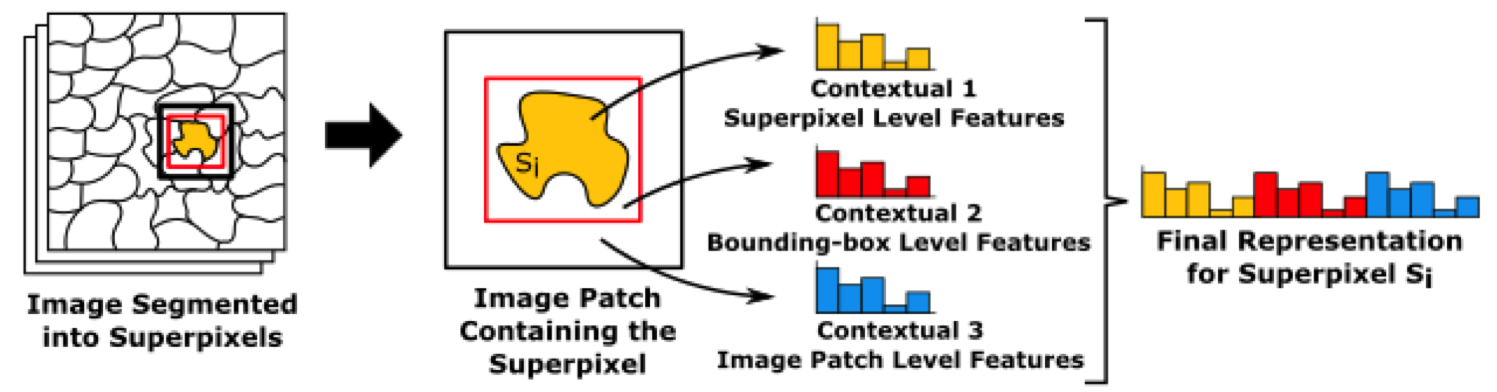
Land-cover maps are one of the main sources of information for studies that support the creation of public policies in areas like urban planning and environmental monitoring. Their automatic creation involves learning to annotate all samples of a Remote Sensing Image (RSI) from just a few annotated by the user. Nevertheless, low-level descriptors like color and shape are not enough to produce a discriminative representation for the samples that represent objects that share similar visual appearance. In order to overcome this limitation, three methods to encode the context of the samples extracted from regions are proposed in this work: the first combines low-level representations from adjacent samples, the second one counts co-occurrences of visual words over a local area and the last one exploits ConvNets to compute deep contextual features. Confirming previous studies, the generated maps were improved by incorporating context in the representations used to feed the classifier.
Some relevant work in this topic are:
| T. Santana, K. Nogueira, A. M. C. Machado, J. A. dos Santos. Deep Contextual Description of Superpixels for Aerial Urban Scenes Classification. In: International Geoscience & Remote Sensing Symposium (IGARSS 2017), 2017, Fort Worth | |
| T. Santana, A. M. C. Machado, A. A. Araújo., J. A. dos Santos. Star: A Contextual Description of Superpixels for Remote Sensing Image Classification. In: CIARP 2016 – XXI Iberoamerican Congress on Pattern Recognition, 2016, Lima. |
Support contact: Tiago Moreira <tiagohubner10@gmail.com>